前言
最近项目需要做一些链路跟踪的需求,以前对zipkin + sleuth 有过了解,但没有自己动手搭建过,借这次的需求手动实践下,顺便写写博客,做做笔记
一、zipkin
1.1 简介
Zipkin是一个分布式跟踪系统,可以搜集服务上报的调用信息,包括http、mysql、redis、mongodb、dubbo等,然后进行相应的展示,上报信息通过traceId进行关联,每个调用就生成一个span,span中有parentId关联上一个span,具体的描述可以参考官网,官网总共没有多少模块,可以看看,github上也有相应的代码。
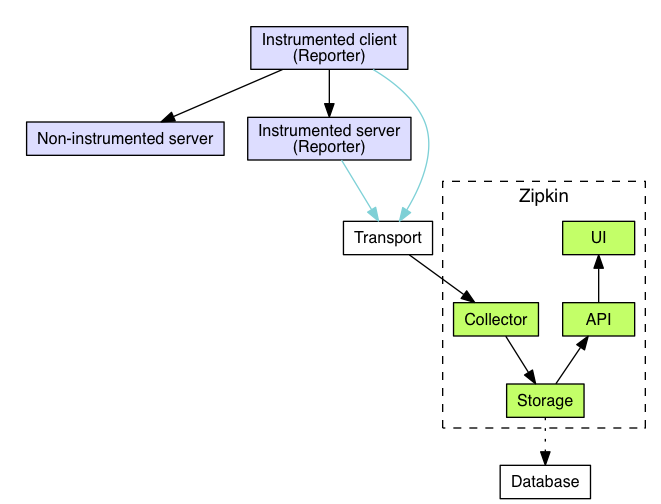
1.2 结构

- Reporter 是集成在服务中的,负责收集相应的信息
- Transport 是将服务上报的信息传输给zipkin的通道,有http、Kafka、Scribe(facebook开源的日志系统)等
- Collector负责收集服务上报的信息,Storage储存到相应的介质,如mysql、es等,api提供http接口返回json数据供UI展示
二、搭建zipkin
zipkin搭建直接用docker,存储用的es
2.1 elasticsearch
docker run -d -p 9200:9200 -p 9300:9300 elasticsearch:6.6.2
# 完成过后,需要进行容器修改跨域设置
docker exec -it 容器id /bin/bash
cd config
vim elasticsearch.yml
# vim 没有的话 需要安装下 apt-get update & apt-get install vim
# 加入下面两行
http.cors.enabled: true
http.cors.allow-origin: "*"
|
2.2 elasticsearch-head
为了方便查看建议安装head插件,5.0 之后的版本已经没有head plugin 了,我这边直接docker安装
docker run -p 9100:9100 mobz/elasticsearch-head:5
# 之后进行使用搜索的时候,会出现406的问题,需要进入head容器里面,修改_site/vendor.js 6886行 7574行,这两处改为
# application/json;charset=UTF-8
|
2.3 zipkin
docker run -d -p 9411:9411 -e STORAGE_TYPE=elasticsearch -e ES_HOSTS=http://真实ip:port openzipkin/zipkin
# --restart=always 这个随个人,可加可不加,加了docker重启,容器会自动重启
|
三、与springboot集成
我用的springboot的版本是 2.2.0.RELEASE
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.0.RELEASE</version>
</dependency>
|
spring.zipkin.base-url=http://localhost:9411/
spring.sleuth.sampler.probability=1
spring.sleuth.web.client.enabled=true
|
3.1 mysql跟踪
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-mysql8</artifactId>
<version>5.9.0</version>
</dependency>
|
spring.datasource.url=jdbc:mysql://ip:port/数据库?queryInterceptors=brave.mysql8.TracingQueryInterceptor&exceptionInterceptors=brave.mysql8.TracingExceptionInterceptor&zipkinServiceName=自己取名字
|
3.3 dubbo跟踪
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-dubbo-rpc</artifactId>
<version>5.4.1</version>
<exclusions>
<exclusion>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave</artifactId>
</exclusion>
</exclusions>
</dependency>
|
dubbo的跟踪需要在resource项目建立 META-INFO.dubbo文件夹,然后新建com.alibaba.dubbo.rpc.Filter 文件,文件中写入
tracing=brave.dubbo.rpc.TracingFilter,然后在 application.properties 文件中配置tracing这个filter
spring.dubbo.consumer.filter=tracing
|
3.4 mongodb跟踪
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-mongodb</artifactId>
<version>5.12.4</version>
</dependency
|
mongodb的跟踪不能通过配置直接解决,需要给mongoClient添加commandListener
@Configuration
public class MongodbConfig {
@Bean
public MongoClientOptions mongoOptions() {
CommandListener listener = MongoDBTracing.create(Tracing.current())
.commandListener();
return MongoClientOptions.builder().addCommandListener(listener).build();
}
}
|
3.4 brave
上面这些能力都是brave提供的j各种 instrumentation java 库,相应的代码可以参考Github
四、展示
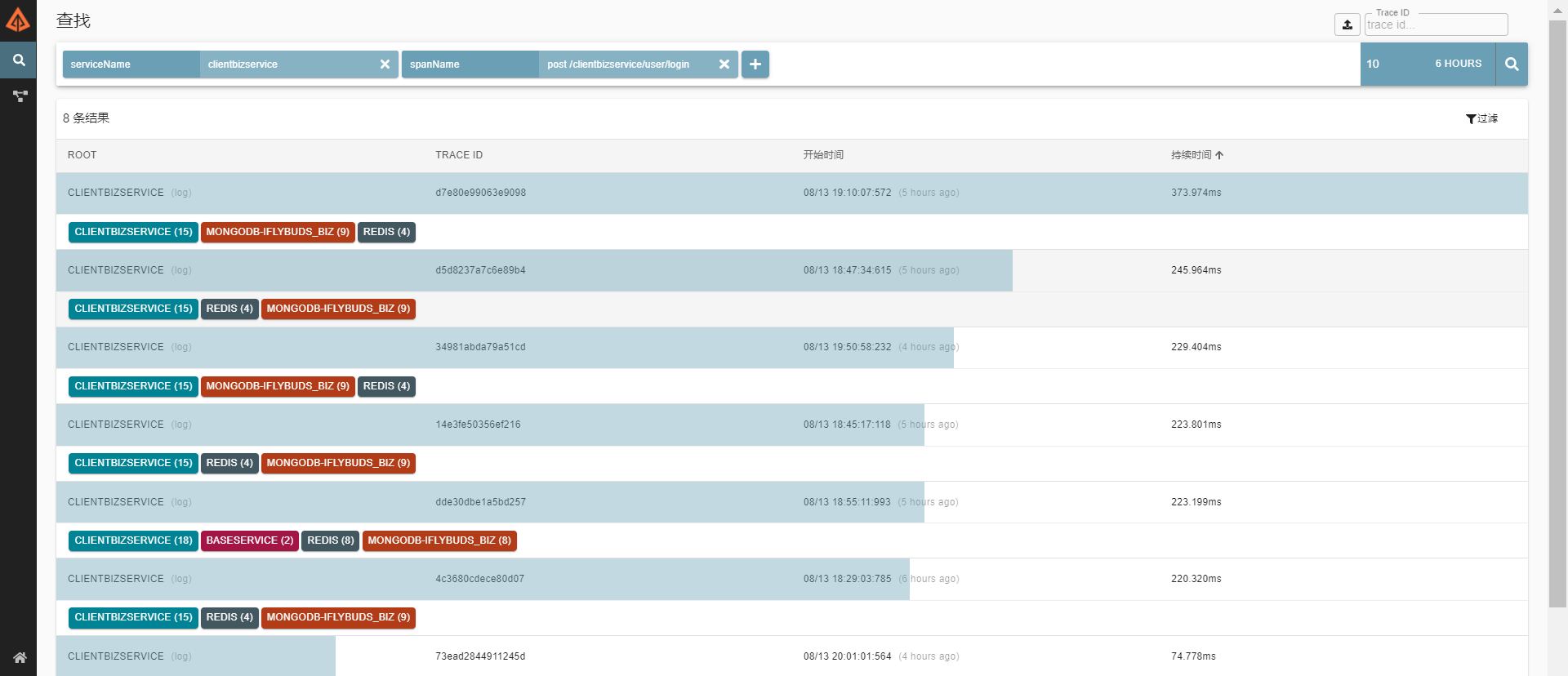
上面两部分完成过后,就还可以访问zipkinUI来,本机部署的话访问 http://localhost:9411,打开后会有相应的展示
相应的搜索条件有 servicename、spanname、tags等,选中一个可以展示详情
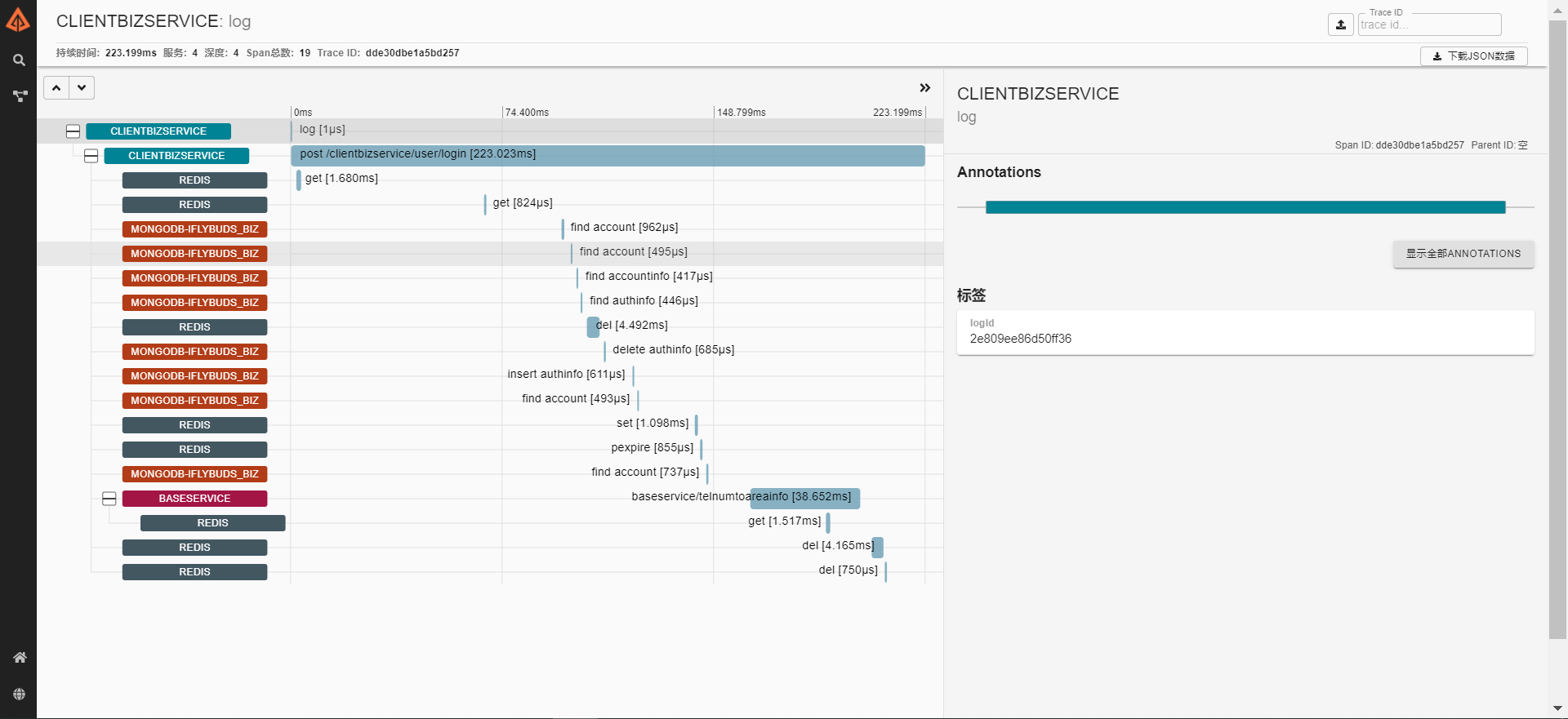
上图中第一个span是我通过置入过滤器直接嵌入的,并且给span打了特定的tag,logId
@Component
@Order(Ordered.HIGHEST_PRECEDENCE)
public class TraceFilter extends OncePerRequestFilter {
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
Span logSpan = null;
try {
Tracer tracer = Tracing.currentTracer();
logSpan = tracer.newTrace().name("log")
.tag("logId", "输入自己想要的值")
.start();
tracer.withSpanInScope(logSpan);
filterChain.doFilter(request, response);
} finally {
if (logSpan != null) {
logSpan.finish(System.currentTimeMillis());
}
}
}
}
|
五、sleuth和zipkin的关系
Sleuth是收集收据的,zipkin是存储展示数据的